
Data mining is een enorm uitgebreid en complex vakgebied. Het gaat over data, business-vraagstukken, techniek, programmeren, methodes en niet te vergeten statistiek en wiskunde. Als je denkt via een beetje googlen een goed beeld van het vakgebied te krijgen, loop je het risico ‘door de algoritme-bomen het analytics-bos niet meer te zien’. De kans is groot dat je belandt op een site waarbij een of ander algoritme wordt toegelicht aan de hand van complexe wiskundige equations. Allemaal erg interessant, maar niet als je als newbie op zoekt bent naar de big picture van data mining. Ofwel, welke algoritmes zijn er? En wat zijn de belangrijkste algoritmes? En welk doel dienen deze algoritmes? En hoe bepaal je welk algoritme gebruikt moet worden? En wat zijn de principes waarop deze algoritmes zijn gebaseerd?
Gelukkig heeft professor Sayad uit Toronto over deze vragen nagedacht. Saed maakt bij data mining een simpel en duidelijk onderscheid in explaining the past via exploration en predicting the future via modeling. Goed om eerst maar eens stil te staan bij exploration voordat we ingaan op modeling. Ofwel, bij het begin beginnen.
Exploratief onderzoek
Saed maakt bij exploratie onderscheid tussen het analyseren van één variabele (univariate) en twee variabelen (bivariate). Bij één variabele heb je dan de bekende statistieken (count, mean, variance, etc.) en grafieken (bar chart, histogram, box plot). Vervolgens splits Saed de methodes voor categorieën en numerieke waarden. Of variabelen (of features, attributes, predictors, etc.) nominaal of numeriek zijn is sterk bepalend voor type statistiek (en type model zullen we straks zien). Daarom wordt bij data mining ook veel aandacht besteed aan converteren van nominaal naar numeriek en vice versa. Dat heet respectievelijk encoding en binning. Zie hieronder de boomstructuur. De meeste statistieken/grafieken zullen bekend voorkomen.
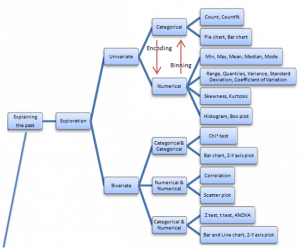
Je kunt stellen dat je deze analyses (exploratie!) uitvoert voordat je met modeling (predicting the future) begint. Je leert de dataset kennen door wat bar charts te maken, wat statistieken op te lepelen (counts, median, standaardafwijking), checks uit te voeren op null-waarden, via boxplots te kijken of je veel outliers hebt en via histogrammen nagaat of de variabele een normaalverdeling kent en wellicht skewness heeft. Allemaal belangrijke aspecten voordat je start met modeling. Immers, je moet wel een beeld hebben welke variabelen voorspellend zouden kunnen zijn en bovendien is datapreparatie cruciaal bij modeling, omdat de data wel aan een aantal randvoorwaarde moet voldoen (bijv. geen null-waarden, een normaalverdeling of alleen numerieke waarden).
“Je leert de dataset kennen door wat bar charts te maken, wat statistieken op te lepelen (counts, median, standaardafwijking), checks uit te voeren op null-waarden, via boxplots te kijken of je veel outliers hebt en via histogrammen nagaat of de variabele een normaalverdeling kent en wellicht skewness heeft.”
Modeling
Ok, en dan nu het echte werk: predicting the future! Dat klinkt spannend, maar dat hoeft het niet altijd te zijn. De methode ZeroR doet niks anders dan de voorspelling baseren op de meerderheid. Stel, je hebt 9 van de 10 examens behaald, dan voorspelt Zero R dat je het volgende examen ook gaat halen. 90% kans dat dit algortime gelijk heeft. Wohhhh, je hebt je eerste voorspellingsmodel onder de knie, gefeliciteerd! In onderstaand boomstructuur zie je dat ZeroR gebaseerd is op frequentie tabellen: ofwel, simpel tellen van aantal voorkomens. Bij ZeroR is dat zeer simpel, bij One R (1 variabele wordt meegenomen) ook, bij naïve bayesian en decision tree wordt het tellen van de frequentietabel al wat lastiger.
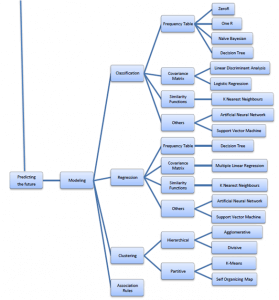
Even terug naar de structuur van de boom. Die geeft immers (deels) antwoord op de vragen: welke algoritmes zijn er en wanneer gebruik je een algoritme? De belangrijkste indelling is het type modeling:
- Classification is a data mining task of predicting the value of a categorical variable (target or class) by building a model based on one or more numerical and/or categorical variables (predictors or attributes).
- Regression is a data mining task of predicting the value of target (numerical variable) by building a model based on one or more predictors (numerical and categorical variables).
- Clustering (also called unsupervised learning) is the process of dividing a dataset into groups such that the members of each group are as similar (close) as possible to one another, and different groups are as dissimilar (far) as possible from one another. Clustering can uncover previously undetected relationships in a dataset.
- Association Rules find all sets of items (itemsets) that have support greater than the minimum support and then using the large itemsets to generate the desired rules that have confidence greater than the minimum confidence. The lift of a rule is the ratio of the observed support to that expected if X and Y were independent.
Met voorbeelden wordt dit nog duidelijker:
- Classification: voorspel of deze klant zijn lening afbetalen of niet (Ja/Nee)? Gaat deze klant weglopen (Ja/Nee)? Is een email spam of niet?
- Regression: Voorspel de lengte van een persoon op basis van gewicht, nationaliteit, geslacht en leeftijd. Door deze 3 onafhankelijke variabelen kan je de afhankelijke variabele redelijk voorspellen. Vanzelfsprekend wel met een foutmarge.
- Cluster: Welke groepen van klanten hebben wij met inachtneming van koopgedrag, contactmomenten en klachten?
- Association rules: Welke artikelen worden er meer dan gemiddeld samen met brood verkocht (bijv. boter)? De bekende basketanalyse.
Hé, dit geeft wel wat overzicht in type voorspellingen van uitkomsten: voorspelling van Ja/Nee (classificatie), voorspellen van numerieke waarde (regressie), voorspellen van cohorente groepjes (clustering) of voorspellen van associatie (association rules). We hebben hiermee al een beter beeld wanneer welk model. Het spotten van mogelijkheden om analytics in zetten (of zoals je wilt: big data analytics) kun je doen door de simpele vraag te stellen (aan jezelf of de klant): wat wil je voorspellen en waarom? Op basis van het antwoord kun je via bovenstaande boom een eerste selectie maken van het juiste algoritme. Dit is geen wereldschokkende constatering, maar ik vind het juist belangrijk om complexe onderwerpen in de basis simpel te houden.
Als je op basis van bovenstaande structuur meer wilt verdiepen in data mining, kijk dan eens naar deze afspeellijst van Noureddin Sadawi. Noureddin houdt de structuur van van Saed aan en geeft meer achtergrond bij het idee/concept/principe van de algoritmes. Tja, dan komen ook allerlei wiskundige vergelijkingen aan de orde. Maar je hoeft deze niet in detail te kunnen doorgronden om wel het principe van een algoritme te begrijpen. Die principes zijn vaak opvallend eenvoudig. Zo wordt een decision tree voor regressie opgebouwd door standaardafwijking per variabele te berekenen om vervolgens de boom te starten met de variabele met de beste information gain. Je kunt stellen dat Noureddin met deze afspeellijst de black box van data mining algoritmes heeft.
Mocht je de afspeellijst niet gaan bekijken, dan toch alvast hier een aantal losse flodders over data mining en de algoritmes:
- Natuurlijk wordt benadrukt dat modellen correlatie bewijzen, maar geen causaal verband.
- Classificatie is een voorbeeld supervised learning, want je vertelt het algortime o.b.v. historische data of iets wel of niet is gebeurd (“deze klanten hebben hun lening niet terugbetaald”), op basis daarvan gaat het model toekomstige gevallen herkennen. Bij clustering vertel je het algoritme niks, het algoritme moet zelf maar clusters maken en daarom heet dat unsupervised learning.
- Classificatie kan gaan over binary classification (ja/nee, o/1 wel/niet), maar ook over multiclass classification (gaat de klant een groene, rode, witte of zwarte auto kopen?). Overigens maken multiclass classification algoritmes gebruik van binary algoritmes.
- De voorspellende kracht van The naive bayesian classifier is ondanks de eenvoud vaak goed en zelfs vaak beter dan meer verfijnde en complexe modellen.
- Ook de Linear Discrimant Analysis is eenvoudig en robuust. Zoekt naar lineaire relatie waarbij een lijn die twee klassen (Ja/Nee) in een scatterplot scheidt.
- Decision trees (beslissing Ja/Nee zie je o.b.v. boomstructuur) kunnen worden gebruikt voor classificatie én regressie. En decision trees kunnen omgaan met categorieën en numerieke waarden. Voordeel van Decision Tree is dat deze voor de mens inzichtelijk blijft (i.t.t. neural netwerk).
- Bij regressie denk je aan het voorspellen van een numierieke waarde. Dat klopt ook bij lineaire en multiple regression. Echter, Logistic regression gebruik je voor classificatie. Het algoritme is welk gebaseerd op (multiple) lineaire regressie, maar leidt niet tot een lijn, maar tot een S-curve waarbij de onderkant ‘Nee’ is en de bovenkant ‘Ja’ (of vice versa).
- K-Nearest Neighbours (KNN) is gebaseerd op het idee dat de klasse gelijk is aan de voorkomens die dicht in de buurt liggen. Bij K=5 kijk je naar de 5 dichtstbijzijnde buren. Hier zie je ook weer een voorbeeld van het belang van datapreparatie: de afstand tussen type variabelen moet wel gelijk zijn. Stel, je hebt variabele salaris en leeftijd, dan heeft salaris veel meer invloed op het mode (want veel meer spreiding en hogere waarden). Dat los je op door de waarden te standaardiseren. Je moet dat wel weten, anders is je voorspelling niet betrouwbaar.
Tenslotte: Om nu te denken dat je het gehele data mining spectrum overziet, toch nog een teleurstellende afsluitende mededeling: Er zijn nog meer algoritmes, denk aan time series and forecasting, netwerkanalyse, text mining, cohort-analyse, etc. Waarom Saed Sahad deze niet heeft opgenomen in de boomstructuur maar wel bij further reading, is mij niet duidelijk. Tijdgebrek? Minder belangrijke algortimes? Ik weet het niet. Tja, daaruit blijkt maar weer: het gehele analytics-bos overzien blijft een analyse op zichzelf.
Meer informatie over data analytics
Wil je graag meer weten over welke data analytics oplossingen jouw organisatie verder kunnen helpen? Neem dan vrijblijvend contact met ons op en we staan je graag te woord over jouw bedrijfsdoelstellingen en hoe data analytics daarbij kan helpen.


