
Zoals wellicht bekend kun je in Tableau ook R code uitvoeren (via Rserve).
Waarom zou je dit willen, een R-Tableau integratie? Mijn ervaring tot nu toe met data exploratie, data visualisatie en (interactieve) dashboarding is dat je ergens moet beginnen, en snel iets concreets moet laten zien aan de stakeholders. Dan pas gaat het leven, wordt men enthousiast, komen er vervolg vragen en worden er middelen beschikbaar gesteld. Tableau leent zich m.i. erg goed voor dergelijke toepassingen.
Wellicht geldt dat ook voor het toepassen van analytics? Hieronder twee eenvoudige praktische voorbeeld use-cases.
Wat heb je nodig? Een (lokaal of op een server) draaiende Rserve, met de benodigde R packages geïnstalleerd (in dit geval: rpart, kmeans, rpart.plot, rattle, RColorBrewer).
Churn prediction: decision tree
Casus: je wilt voorspellen welke klanten een groot risico hebben binnen een bepaalde periode weglopen
Dit kun je doen door een decision tree model te creëren (trainen).
Hiervoor heb je een dataset nodig met historische gegevens op klant-niveau waarvan bekend is of deze klanten (in de periode erna) zijn weggelopen of niet. Deze dataset moet een of meerdere velden bevatten waarvan je vermoedt dat deze van invloed kunnen zijn op het al dan niet churnen van de klant. (De ‘kwaliteit’ van de variabelen is overigens zeer belangrijk voor de bruikbaarheid, niet te veel null-values, etc.)
Deze dataset kun je gebruiken om het algoritme het model te laten trainen en daarmee een classification tree genereren. De tree laat zien welke variabelen van invloed zijn op de te predicten value (churn ja/nee).
Voor dit voorbeeld heb ik een example dataset gebruikt van een telecom bedrijf.
Hieronder een screenshot van een heel eenvoudige tree:
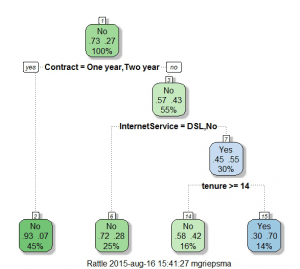
Op zichzelf kan dit al een waardevolle inzichten opleveren. Hieruit blijkt bijvoorbeeld dat klanten met een maandelijks opzegbaar abonnement véél vaker zijn weggelopen dan degene met een contractduur van 1-2 jaar. Dit is natuurlijk zeer voor de hand liggend, maar wanneer het model is opgebouwd met tientallen variabelen kun je op deze manier patronen herkennen die je anders niet waren opgevallen. Bijvoorbeeld dat klanten die naast DSL ook een betaald security-pakket afnemen relatief vaak weglopen; misschien krijgen ze dit security-pakket er bij een concurrent gratis bij een DSL abo waardoor ze overstappen?
Dit model kun je ook gebruiken om een voorspelling te doen voor je huidige klanten. Ik heb een test dataset in Tableau geladen waarvan de outcome al wel bekend is, om zo te kunnen bekijken hoe het model presteert.
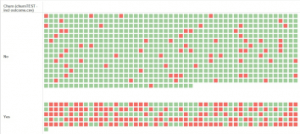
Zoals uit bovenstaande viz blijkt ziet is de voorspelling in ieder geval vaker goed dan fout 😉. (De rijen zijn de actuals, de gekleurde blokjes zijn de predicted values.) Indien gewenst kan getracht worden het model betrouwbaarder te krijgen door met de parameters te spelen, meer training data er doorheen te jagen, betere (samengestelde/geaggregeerde) variabelen te gebruiken, of misschien wel door een ander algoritme te kiezen.
Customer clustering: kmeans
Casus: je wilt je klanten segmenteren om zo een beter inzicht te verkrijgen, en bepaalde klantclusters gerichter kunt targetten met een marketing campagne.
Hiervoor kun je gebruik maken van het kmeans algoritme. (Zie deze post van Rick voor meer uitleg over dit algoritme.)
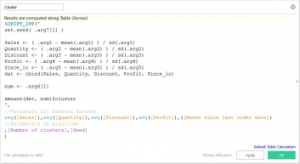
Op vergelijkbare manier kun je het in een Tableau calculated field stoppen:
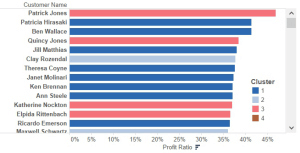
De gevonden clusters kun je vervolgens verder gaan analyseren. Hieruit blijkt bijvoorbeeld dat een van de clusters bestaat uit klanten die al lange tijd niets meer besteld hebben, en dat van de klanten met de hoogste profit-ratio er zich een groot deel in dit cluster bevindt.
Door Mark Griepsma



{kind=link}