
Optimalisatie van Power BI met Direct Query (DQ) op Snowflake is dé oplossing voor snel, kostenefficiënt en AVG-proof werken in Power BI. Helaas is Direct Query vaak te traag gebleken. Het is ons gelukt om de performance significant te verbeteren: bijna 10 keer zo snel! Ontdek in deze blog hoe we dit hebben bereikt.
Een architect wil niet twee keer dezelfde handelingen uitvoeren, een gebruiker wil een snel dashboard en de CFO wil zo min mogelijk kosten maken. Ondertussen vereisen AVG-regels dat gebruikers alleen zien wat ze mogen zien. Dit alles is mogelijk met Snowflake & Direct Query in Power BI. We laten hierbij het traditionele dimensioneel modelleren van Ralph Kimball (sterschema’s) los om de beste performance te bereiken.
Met Snowflake als onze analytical database kunnen we een One Big Table (OBT) modelleren. Daarmee heb je geen losse dimensies meer nodig, wat leidt tot een betere query performance. We vertellen je er graag meer over.
Nadelen van de standaard opslagmodus ‘Import’
In de Power BI community is ‘Import’ de standaard opslagmodus voor Power BI. De data wordt dan in Power BI opgeslagen. Het belangrijkste voordeel van de Import modus is dat de performance voor de gebruikers zeer goed is. De keerzijde is dat de data zowel in het dataplatform als in Power BI wordt opgeslagen, wat meerdere nadelen heeft.
Nadelen
- Hogere kosten, doordat grotere capacity (Premium) in Power BI nodig is
- Minder efficiëntie, doordat functionaliteit op meerdere plekken moet worden geïmplementeerd
- Foutgevoeliger, doordat de Power BI imports moeten worden gescheduled en gemonitord
- Onveiliger, doordat persoonsgegevens ook in Power BI moeten worden afgeschermd
Implementatie van de AVG-oplossing
Als we werken met persoonsgegevens (PII = Persoonlijk Identificeerbare Informatie) moeten we in het dataplatform maatregelen nemen waardoor die persoonsgegevens alleen leesbaar zijn voor medewerkers met de juiste rechten: een medewerker van HR ziet op een rapportage volledige postcodes, maar een medewerker van marketing ziet alleen de eerste vier cijfers. In de door Inergy ontwikkelde AVG-oplossing op basis van het Snowflake dataplatform is functionaliteit beschikbaar om dit te doen, ook op grote datasets.
Bij het gebruik van de Import opslagmodus in Power BI moet de data zowel met als zonder PII worden opgeslagen in een Power BI dataset en wordt in Power BI afgeschermd wie welke data mag zien. Dit leidt tot dubbele opslag, meer verbruik en beheer en onderhoud op meerdere plekken.
Direct Query als alternatief
Het alternatief is de modus ‘DirectQuery’. Daarbij wordt de data niet geïmporteerd in Power BI, maar worden de query’s rechtstreeks vanuit Power BI doorgestuurd naar Snowflake. Een belangrijk voordeel bij deze opslagmodus in de context van dit onderzoek is dat de AVG-oplossing die in Snowflake is geïmplementeerd, benut wordt door Power BI.
Omdat een gebruiker ingelogd is wanneer hij of zij het rapport gebruikt, wordt zijn of haar gebruikersnaam doorgestuurd naar Snowflake en kan Snowflake bepalen of de data al dan niet geanonimiseerd dient te worden teruggegeven. Een elegante, en qua beheer en opslag, efficiënte oplossing.
Snelheid was het struikelblok bij Direct Query
Helaas is Direct Query vaak te traag gebleken. Eén van de verklaringen hiervoor is dat Power BI voor iedere visual op het scherm een query naar de achterliggende database stuurt. Voor sommige dashboards kunnen dat er tientallen zijn. Zelfs voor een snelle database als Snowflake kost het gewoon meerdere seconden om een dergelijk aantal query’s af te handelen.
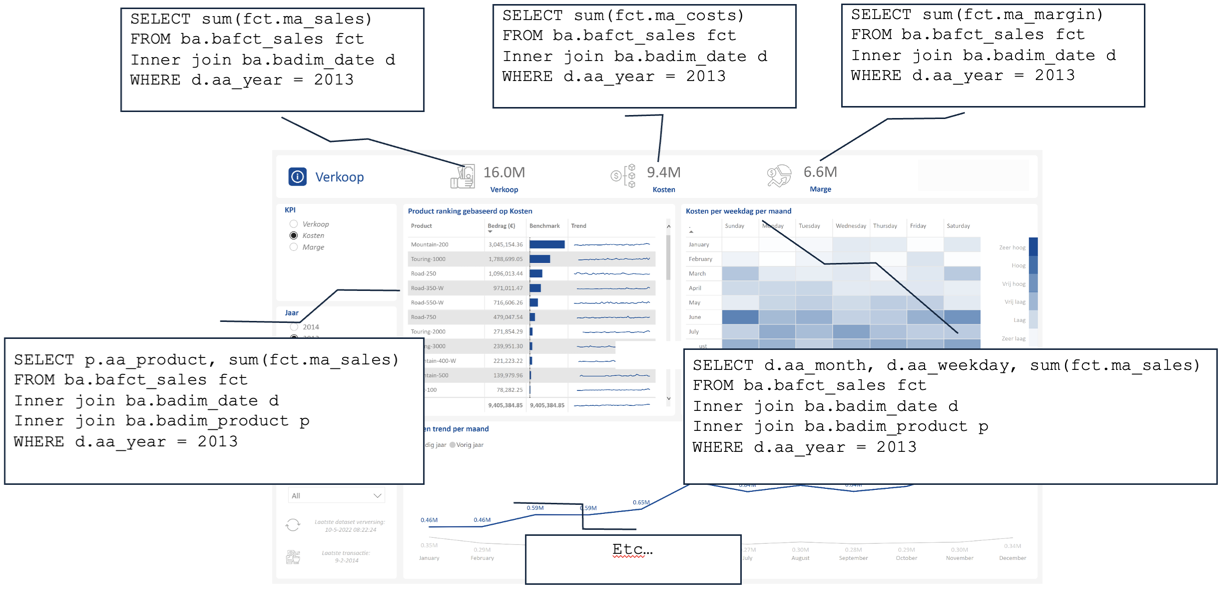
Het is met de nodige inspanning en creativiteit gelukt om de performance van de testpagina te verbeteren van een gemiddelde testscore van 7.879 ms over drie testgevallen, naar een gemiddelde van 873 ms over drie testgevallen, dus bijna 10 x zo snel! Daarbij zijn er slechts zeer beperkte concessies gedaan aan de visuele kant van het rapport.
Stappenplan voor superperformance met Direct Query in Power BI
Snowflake – Warehouse settings
In Snowflake zijn er diverse instellingen mogelijk die de performance beïnvloeden. Allereerst kijken we naar het Virtual Warehouse. Het Virtual Warehouse levert de rekenkracht om gegevens op te vragen.
- Virtual Warehouse size
Je kunt verschillende groottes kiezen voor het warehouse. Vergroot het warehouse niet zomaar van XS naar S of M. De praktijk wijst regelmatig uit dat een groter warehouse opvallend genoeg leidt tot verminderde performance. Bij veel data en/of complexe query’s is het aannemelijker dat een groter warehouse wel een positief effect heeft, aangezien in dat geval het werk wordt verdeeld over meerdere machines. De verklaring dat het in ons geval geen effect heeft, kan liggen in het feit dat verdelen van het werk meer tijd kost dan wat het aan tijdsbesparing oplevert. - Query Acceleration
De Query Acceleration feature van Snowflake versnelt het bevragen van grote tabellen. In dit onderzoek heeft dit een positief effect op de performance, maar de tijd (lees: meer ervaring met Direct Query bij verschillende projecten) moet uitwijzen of dat altijd zo is. Activeer Query Acceleration op het warehouse en meet het effect op de performance om te bepalen of deze optie in jouw geval slim is om toe te passen.
Snowflake – Model
Naast het Warehouse is ook het gehanteerde datamodel van grote invloed op de performance. Het sterschema is sinds jaar en dag de manier van het ontwerpen van BI datamodellen. Dat pad verlaten we voor onze dashboards.
- Maak een One Big Table
Maak een tabel op basis van het feit en de omliggende dimensies. Kies hiervoor alle attributen (meetwaarden en dimensie-attributen) die nodig zijn voor het dashboard (of meerdere dashboards). Sla dit op in 1 tabel, de One Big Table. Dat is één tabel met alle informatie uit het informatiegebied, dus zonder losse dimensietabellen.
In Snowflake kunnen we dit realiseren door een Dynamic table te definiëren. Dit is een soort database view die door Snowflake fysiek in de database wordt weggeschreven. Maar uiteraard is het ook mogelijk om hiervoor een ETL proces te maken.
Soms kan het echter nodig zijn om naast One Big Table extra tabellen aan te maken. Deze tabellen zijn kleine subsets van dimensies, die bijvoorbeeld nodig zijn in de volgende gevallen:
- Optimaliseren van Selectors die een slechte performance hebben of een zoekfunctie gebruiken die niet case sensitive mag zijn.
- Het koppelen van meerdere feitentabellen die op één rapportpagina worden gebruikt en die niet kunnen worden samengevoegd in één One Big Table.
- Maatwerk aggregaat. Naast het maken van de One Big Table kan het ook interessant zijn om in Snowflake een Materialized view te definiëren waarin gegevens uit de One Big Table op een geaggregeerd niveau worden berekend. Als je dashboard bestaat uit detail pagina’s maar ook informatie per maand laat zien, kan dit een handige optie zijn. Snowflake zal namelijk automatisch de geaggregeerde informatie uit de Materialized view gebruiken als dat voor de betreffende rapportpagina volstaat. De performance kan daardoor nog verder verbeteren.
- Clustering key. Dit bepaalt de sortering waarop de data wordt opgeslagen. Door de clustering key te baseren op de selectors op het dashboard, zal Snowflake nog sneller de gevraagde selectie van data kunnen opleveren. Experimenteer hierbij met de volgorde van velden in de clustering key.
- Alle logica in Snowflake. Idealiter wil je in Power BI alleen maar SUM-achtige berekeningen op kolommen hoeven doen. Hierdoor wordt alleen de data die nodig is voor de rapportage opgevraagd in Power BI. Voor een optimale performance voor de gebruiker is het soms nodig om daar goed bij stil te staan, bijvoorbeeld:
- Probeer averages, etc. te vermijden
- Maak een extra kolom aan in de OBT voor iedere meetwaarde waar je in Power BI nog vaste filters op toepast.
- Als je in Power BI kolommen van elkaar aftrekt, neem die berekening dan op in de One Big Table.
Power BI – Semantische laag
Ook in Power BI zijn er diverse manieren om een oplossing te realiseren en de keuzes die je hier maakt, zijn van invloed op de performance van je dashboard.
- Beperk joins.
De querytijd neemt snel toe wanneer er veel joins zijn. Probeer joins daarom te vermijden, bijvoorbeeld door één One Big Table (één tabel) per pagina te gebruiken. - Dual dimensies.
Wanneer je toch met (selector)-dimensies werkt gebruik dan opslagtype ‘Dual’. Dual importeert de betreffende dimensiewaarden vooraf in Power BI en geeft betere resultaten dan Direct Query, zelfs al wordt de volledige query in Snowflake uitgevoerd. Uitzondering hierop zijn dimensies met persoonsgegevens (bijvoorbeeld Medewerker) die in verband met AVG alleen voor geautoriseerde gebruikers leesbaar moeten zijn. In geval van geïmporteerde data is het niet meer mogelijk om de data te maskeren afhankelijk van de rol van de gebruiker. - Referential Integrity.
De Referential Integrity optie vertelt Power BI dat het datamodel integer is, dus dat joins tussen tabellen niet leiden tot verlies van data. Zorg dat je deze optie aanvinkt. Je krijgt inner joins in plaats van left joins en dat geeft een betere performance. - Optimaliseer DAX.
DAX is de ‘programmeertaal’ van Power BI. Experimenteer en kijk wat de beste resultaten geeft:- Probeer zoveel mogelijk met ‘SUM(Tabel[Kolom]) te werken door aanpassingen in Snowflake te doen waar nodig. Zie ook ‘Snowflake – Model’.
- Met name bij tijdberekeningen is de DAX-code het waard om mee te experimenteren. Onderzoek de Snowflake query’s. Dit kan enorme winst opleveren voor de performance. Wat aandachtspunten staan bij de tweede bullet onder het kopje ‘Advies: zelf testen!’
Power BI – Visueel
Ook het visualiseren in Power BI heeft invloed op de uiteindelijke performance die de gebruiker ervaart. Kijk maar naar onderstaande tips:
- Beperk Query’s
- Beperk het aantal visualisaties op een pagina.
- Voeg visualisaties samen in één visualisatie. Met wat creativiteit is er geen zichtbaar verschil voor de gebruiker, maar op de achtergrond kunnen query’s nu gecombineerd worden verwerkt door Snowflake.
- PowerPoint achtergrond.
Je Power BI dashboard bestaat uit een heleboel visuele objecten, zoals grafieken, tabellen en selectors. Maar zelfs de statische objecten zoals tekstvakken, kleurvakken en logo’s moeten door Power BI neergezet worden en dat kost tijd.
Maak in PowerPoint de achtergrond van je rapportpagina en importeer deze als kant en klare achtergrond in Power BI. Neem daarin alle statische onderdelen van de pagina op, zoals kleuren, vormen, teksten, iconen en logo’s. Hiermee voorkom je dat bij iedere klik in het rapport alle objecten opnieuw worden geladen. Wij hebben in onderzoek gezien dat dit echt een verschil maakt. - Ga slim om met slicers.
Slim omgaan met slicers loont de moeite.- Gebruik een ‘Apply all filters’ knop. Zo worden er niet tussentijds allemaal queries verzonden voor tussenresultaten waar de gebruiker niet in geïnteresseerd is.
- Combineer slicers (bijvoorbeeld jaar-week ipv jaar en week). Als je meerdere hiërarchieën wilt kun je bijvoorbeeld een slicer ‘jaar’, een slicer ‘jaar-maand’ en een slicer ‘jaar-week’ maken.
- Probeer zoekfunctionaliteit op Direct Query (AVG) tabellen te vermijden, want bij elke letter stuurt Power BI een query naar Snowflake. Daarnaast is de zoekfunctie bij Direct Query case sensitive en krijg je dus soms geen resultaat op je imperfecte zoekterm.
Advies: zelf testen!
Natuurlijk kun je bovenstaande tips prima uit te voeten, maar iedereen heeft andere data. Het is dus belangrijk om goed te kijken hoe deze tips op jouw data uitwerken. Hoe je dat doet? Lees snel verder.
- Performance Analyzer.
We kunnen van alles meten in Snowflake, maar uiteindelijk gaat het om hoe snel Power BI de cijfers teruggeeft. Dat meet je met de Performance Analyzer in Power BI Desktop. Je ziet in de Performace Analyzer precies hoe lang het opbouwen van de rapportpagina duurt, van het ophalen van de data tot aan het weergeven van de pagina. - Analyseer Snowflake query history.
Snowflake geeft veel inzicht in wat er onder de motorkap gebeurt via de Query History. Kijk naar het aantal queries dat tegelijk naar Snowflake wordt verzonden, de duur, de totale doorlooptijd van het pakket aan queries, en de querystructuur. Hieraan kun je zien of er misschien nog optimalisatie mogelijk is door visualisaties te beperken in Power BI. - Let op afwijkingen.
Zitten er grote afwijkingen (tot factor 5) binnen dezelfde testgevallen op andere momenten? Deze afwijkingen kunnen we op dit moment nog niet verklaren. Check scenario’s daarom direct achter elkaar en hanteer meerdere testgevallen om een goed beeld te krijgen van het effect van je aanpassing.
Aandachtspunten
- Verhoog maximaal aantal connecties.
In het geval van een Premium capaciteit kan je de performance verder verbeteren door het maximale aantal connecties naar de databron te verhogen (van 10 tot maximaal 30). Door het verhogen van het maximum aantal connecties voorkom je dat queries in de wachtrij komen.
- Automatic aggregations.
In het geval van een Premium capaciteit kunnen automatic aggregations een boost geven aan de performance van Direct Query. - Let op de Snowflake kosten.
Het effect van een DirectQuery opslagmodus op het Snowflake verbruik hebben we niet onderzocht, maar het kan leiden tot hogere Snowflake kosten. Aan de andere kant kan Direct Query mogelijk ook kosten besparen op andere gebieden, zoals beheeruren en kosten voor Premium capaciteit in Power BI.
Wanneer wel of geen OBT?
Natuurlijk is het belangrijk om te kijken of voor jouw situatie de OBT-werkwijze handig is. Daarom bespreken we nog een aantal aspecten die van invloed zijn op deze keuze. Een OBT maak je primair om te zorgen dat je een goede Direct Query performance voor je standaard dashboard krijgt. Eenvoudigere queries zorgen daarvoor. In een dashboard met gegevens uit meerdere informatiegebieden moet je werken met selector dimensies om synchronisatie van de selecties (bijvoorbeeld jaar) over verschillende visuals mogelijk te maken. Kimball noemt dit soort gegevens geconformeerde dimensies. Uit onze testen blijkt dat:
- Een enkele OBT veruit de beste performance biedt:
Alle informatie staat klaar via alle benodigde doorsnijdingen - Berekeningen op Facts gaan erg efficiënt:
Hoe meer berekeningen er op facts worden uitgevoerd, hoe groter de relatieve performancewinst is. - Performancewinst neemt af met toenemend aantal selector dimensies
Meerdere OBT’s werken ook snel, maar hoe meer selector dimensies je toevoegt, hoe minder de relatieve performancewinst wordt. Voor een selfservice omgeving met meerdere informatiegebieden en geconformeerde dimensies is OBT dus niet de gewenste oplossing.
Afsluitend
Kom je tot andere conclusies dan wat wij je in dit artikel vertellen? Mooi! Ik hoor dat graag en dan kunnen we onderzoeken waar het door komt. Zo krijgen we met elkaar steeds een beter begrip van het optimaliseren van Direct Query op Snowflake.
Wil je meer weten? Vraag het ons!
Wil je verder sparren over Direct Query op Snowflake? Neem dan vrijblijvend contact met ons op. Neem dan vrijblijvend contact met ons op. Eén van onze specialisten neemt binnen één werkdag contact met je op.

Boek direct een gratis adviesgesprek met Peter
✔ kies zelf je dag en tijd ✔ gratis en zonder verplichtingen


