
Mijn naam is Lieselotte en ik ben developer bij Inergy. Elke dag programmeer ik voor toffe projecten bij verschillende klanten. Ik spijker mijzelf continu bij op wat meer algemene basis kennis van de IT. Aangezien onze slogan luidt: “Let’s play create and grow together”, dacht ik: “OK! Let’s learn together”. Of je nu net als ik nieuwsgierig bent naar deze IT onderwerpen of dat je wel houdt van een recap momentje, lees dan lekker verder. In deze blog ga ik dieper in op het breadth first search algoritme.
Momenteel ben ik bezig met het bestuderen van verschillende algoritmes. Ik begon mijn zoektocht met het boek “Algorithms – An illustrated guide for programmers and other curious people” door Aditya Y. Bhargava. In dit boek worden bekende algoritmes op een makkelijke manier uitgelegd (vol met plaatjes en voorbeelden, perfect!).
Wat is een algoritme?
Laten we kort even herhalen wat een algoritme ook al weer is. Een algoritme wordt beschreven als een set van instructies om een bepaald doel te bereiken. Elk stuk code dat geschreven word is dus een algoritme. Algoritmes worden interessant wanneer ze een efficiënte oplossing bieden voor complexe problemen.
In deze blog gaan we het Breadth-first search door een bedachte probleemstelling bekijken.
Een algoritme wordt beschreven als een set van instructies om een bepaald doel te bereiken.
Breadth first search algoritme
Stel je voor dat we bij Inergy hard opzoek zijn naar een nieuwe developer. Deze persoon willen wij het liefst vinden via onze eigen connecties op LinkedIn. Om onze recruiters te helpen gaan we een stukje code schrijven die deze persoon aandraagt.
Probleem: Is er een developer in onze connecties die nog niet voor Inergy werkt? Is het antwoord ja, dan willen we als eerst de dichtstbijstaande connectie krijgen.
Om dit voor elkaar te krijgen, zullen we eerst moeten zoeken in jouw eigen set van connecties (of de persoon die de software gebruikt). Heb jij geen developer in jouw connecties dan moeten we gaan zoeken in de connecties van jouw connecties (tweedegraads connecties) en daarna verder zoeken in de derdegraads connecties, enzovoorts.
Om deze zoektocht te doen, maken we een lijstje van onze connecties. We beginnen bij onze eigen connecties en kijken bij elk persoon of dit een developer is. Is het antwoord ja, dan zijn we klaar. Zo niet dan voegen we al zijn connecties toe aan onze lijst en gaan we naar de volgende op ons lijstje en strepen we de gecheckte connectie door. Hieronder heb ik een voorbeeld van zo’n netwerk gevisualiseerd.
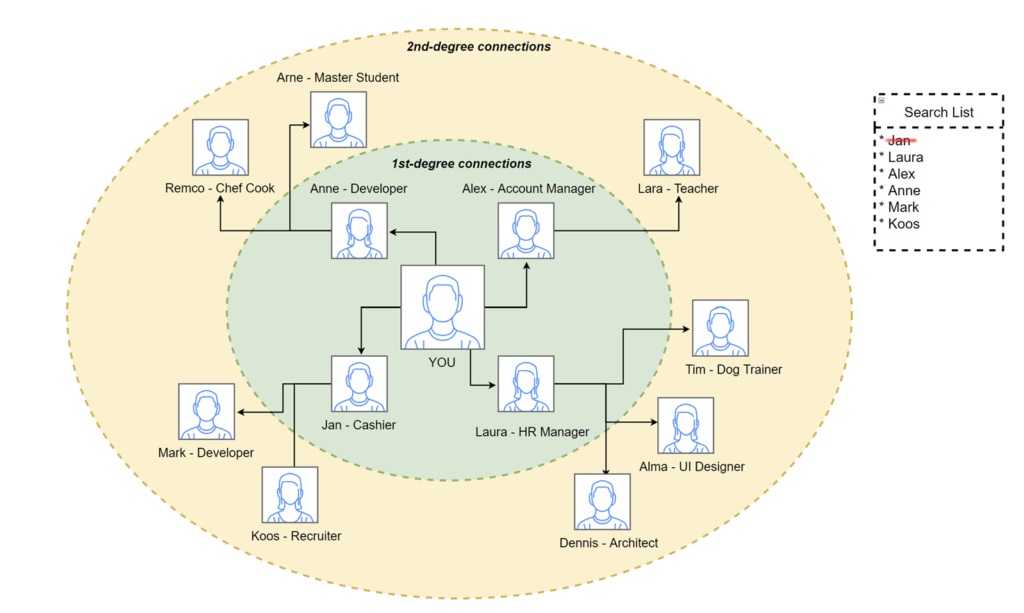
Gebruik een queue
Het algoritme werkt alleen wanneer we gebruik maken van een speciale lijst, een zogeheten “queue”. De naam verklapt zijn eigenschap: het is een soort wachtrij waar de eerste die erin komt ook de eerste is die eruit gaat. In een queue worden nieuwe “items” altijd achteraan de rij toegevoegd. Kijk nu nog een keer naar het plaatje van connecties. Stel je voor dat in ons voorbeeld Mark was toegevoegd vóór Anne. Het gevolg zou zijn dat Mark uit ons algoritme komt terwijl Anne een eerstegraads connectie is en Mark een tweedegraads.
Het breadth first search algoritme in code
Oke, laten we nu het algoritme schrijven in een stukje code. Ik heb gekozen om het stukje in Python te schrijven, aangezien de meeste mensen Python makkelijk lezen en anders is het ook een relatief makkelijke taal om mee te beginnen! Tip: mocht je geen Python geïnstalleerd hebben maar je wilt wel even spelen met het algoritme, gebruik dan Jupyter Notebook of Replit in de browser (geen installatie nodig).
Stuur ons gerust een e-mail als je deze code in tekst wil ontvangen.
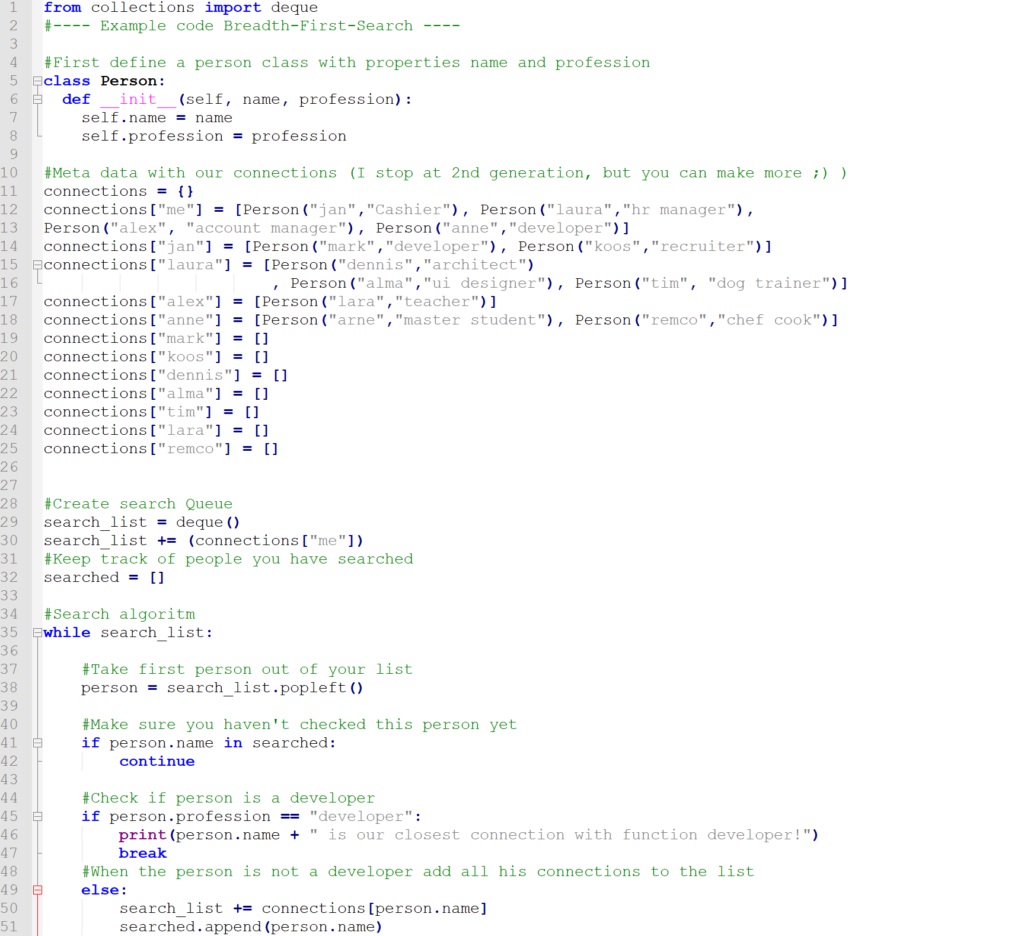
Voorkom een oneindige cirkel
Als je goed kijkt naar de code, dan zie je dat ik nog iets heb verzwegen. We houden ook bij wie we al hebben onderzocht. Probeer te beredeneren waarom dit noodzakelijk is, voordat je verder leest. Als we niet bij houden wie we hebben onderzocht, zouden we terecht kunnen komen in een oneindige cirkel. Stel je voor dat jij een connectie hebt met Jan. Dan heeft Jan ook een connectie met jou. Wanneer het algoritme Jan heeft gecheckt, voegt hij al zijn vrienden toe, waaronder jijzelf. Zonder te checken of het algoritme jou al heeft gecheckt, checkt hij jou opnieuw en zal hij daarna weer alle vrienden toevoegen inclusief Jan! We vermijden dus een oneindige loop door bij te houden wie al onderzocht zijn.
Het Breadth first search algoritme is inzetbaar voor veel meer problemen dan alleen dit voorbeeld. Het algoritme beantwoordt de soort vraag is er een weg van A naar B en zo ja, wat is dan de weg met het minst aantal stappen?
Bedankt voor het lezen van deel 1!
Dit was deel 1 van de serie Let’s Learn about algorithms. In deel 2 kijken we naar het Dijkstra algoritme. We kijken dan naar de verschillen tussen Breadth first search en het Dijkstra algoritme, onderzoeken we welke van de twee soorten algoritmes je gebruikt in welke situatie en schrijven we een voorbeeld-Dijkstra-algoritme.


