
Remo is consultant bij Inergy, werkt op dagelijkse basis met Power BI en ondersteunt klanten in het gebruik. In deze blog neemt hij je mee in het verkleinen van de opslaggrootte in Power BI. Power BI wordt binnen veel organisaties gebruikt als dé tool om dashboards en rapportages op te leveren. Maar hoe zorg je ervoor dat de prestatie van de dashboards niet tegenvalt? In deze blog gaat Remo dieper in op het verbeteren van Power BI performance door de opslaggrootte van de dataset aanzienlijk te verkleinen.
De opslaggrootte van je Power BI dataset
Over het algemeen geldt, ‘hoe groter de dataset, hoe langzamer de rapporten’. Denk maar aan een Excelbestand waarbij een bestand met veel rijen aan data snel vastloopt. Hoe meer rijen, hoe langzamer je filters reageren en hoe groter de kans dat Excel vastloopt. Maar welke zaken zorgen er nou voor dat mijn Power BI dataset in omvang toeneemt?
Voorbeeldsituatie
Voor de uitleg in deze blog gaan we uit van de volgende situatie:
- We beschikken over een datawarehouse met verkoopgegevens van een retailorganisatie. De organisatie heeft 100 winkels, die elk 5.000 klanten per dag hebben, die elk 10 producten kopen.
- In het dataplatform wordt informatie op het allerlaagste, meest gedetailleerde niveau vastgelegd. Voorbeeld: elke kassabonregel (elk verkochte product) heeft een eigen rij met data in het dataplatform.
- Power BI kent twee modi, Import en Direct Query (we gaan hier verder niet op in). We maken gebruik van de modus Import, waarbij de data wordt opgeslagen in Power BI.
Tabellen
De data waar Power BI mee werkt wordt opgeslagen in tabellen. Een tabel bestaat uit rijen en kolommen. In een tabel van 10 rijen (observaties) en 10 kolommen (kenmerken) heeft 100 cellen. In elke cel staat een waarde, die een beschrijving geeft van het kenmerk voor die specifieke observatie. De opslagruimte die nodig is voor één tabel is afhankelijk van het aantal rijen, het aantal kolommen en de waardes in de cellen.
Lees ook:
Verbeter datakwaliteit met Critical Data Elements
Beperk het aantal rijen
Hoe meer rijen met data er moeten worden opgeslagen, hoe meer geheugen daarvoor nodig is. Maar hoe beperk je nou het aantal rijen in een Power BI dataset?
Data aggregatie
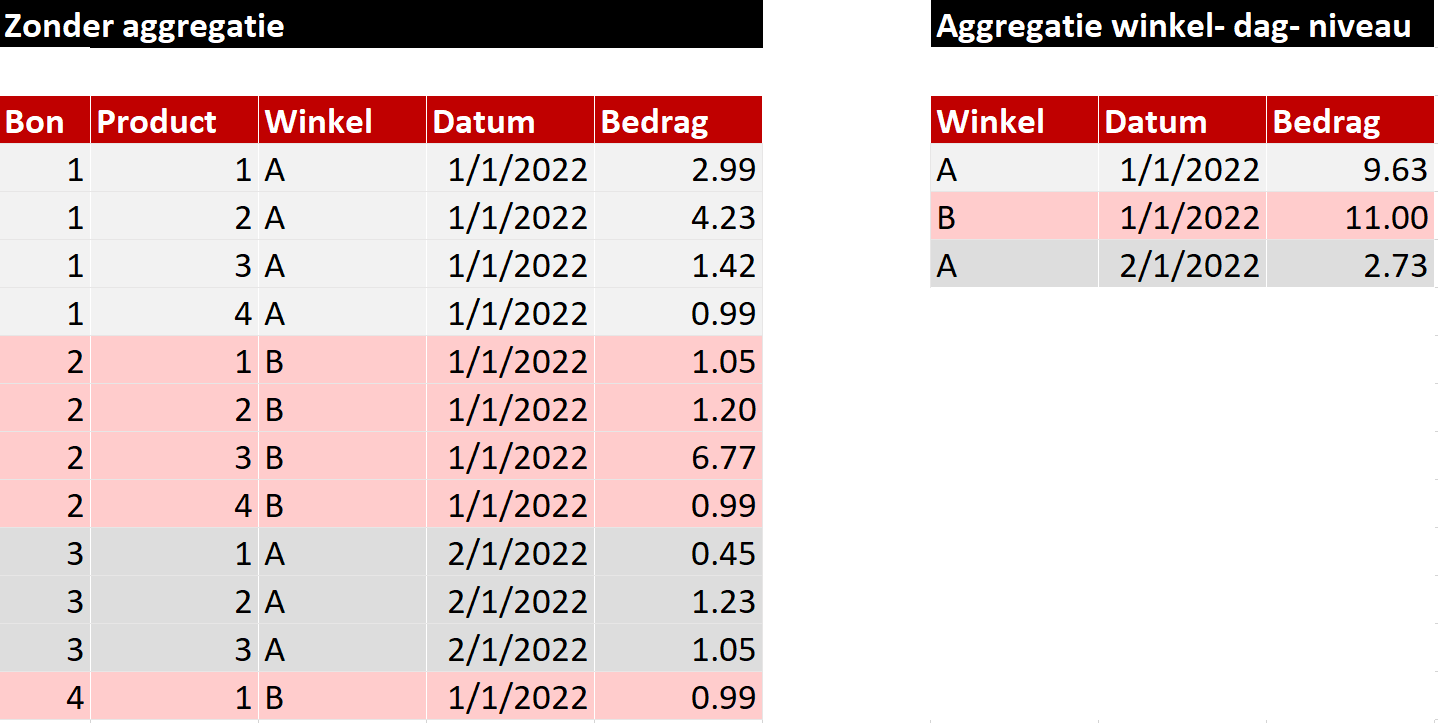
Als de data in het dataplatform op het meest gedetailleerde niveau is opgeslagen, maar de businessvraag niet over dat detailniveau gaat, dan is het zonde de data op dat niveau op te slaan. Het is dan beter om op te tellen (aggregeren) naar een hoger niveau. Bijvoorbeeld: In plaats van de omzet op bonregel te importeren naar Power BI, kan dit op winkel-dagniveau.
Als we alle bonregels uit het voorbeeld in Power BI zouden inladen, hebben we voor één jaar voor alle winkels 365*100*5000*10= 1.825.000.000 (1.8 miljard) rijen nodig.
Dezelfde som op winkel-dagniveau levert: 365*100= 36.500 rijen. Een verschil van factor 50.000.
Stel jezelf altijd de vraag of je het correcte aggregatieniveau te pakken hebt om de businessvragen te beantwoorden, zonder dat je onnodig veel rijen importeert.
Voorbeeld van aggregatie
Beperk de datahistorie
Naast het kiezen van het juiste agreggatieniveau, is het belangrijk te bedenken hoeveel historische data je wil bewaren. Hoe meer historie je wilt behouden, hoe meer rijen je nodig hebt. Is alle historische data die nu is ingeladen écht nodig hebt voor het beantwoorden van de structurele businessvragen? Het halveren van het aantal jaren historische data kan de grootte van het model maarliefst halveren. Denk ook goed na over het type Slowly Changing Dimensions (SCD) dat je toepast. Ook dit heeft een grote impact op de performance van je datawarehouse.

Boek direct een gratis adviesgesprek met Peter
✔ kies zelf je dag en tijd ✔ gratis en zonder verplichtingen
Beperk het aantal kolommen
Tabellen worden in Power BI per kolom opgeslagen en de opslagruimte is afhankelijk van de inhoud van de kolom. Wat kun je doen om de opslagruimte van de kolommen in je dataset te beperken?
Verwijder ongebruikte kolommen
Zijn er kolommen met daarin informatie die je niet gebruikt voor het beantwoorden van de businessvragen? Dan is het advies deze niet te importeren. Als je dit wel doet, nemen ze onnodig opslagruimte in beslag en maken daarmee je dataset onnodig trager.
Kardinaliteit en data dictionaries
Soms is het opsplitsen van data van 1 kolom naar 2 kolommen juist wél een goed idee. Dit is een gevolg van de kardinaliteit. kardinaliteit in Power BI geeft aan hoeveel unieke waardes er zijn in een kolom. Als een kolom slechts twee mogelijke waardes heeft (bijvoorbeeld ‘Ja’ of ‘Nee’), dan is de kardinaliteit twee. Hoe hoger de kardinaliteit, hoe meer verschillende waarden opgeslagen moeten worden.
Lees ook:
Waarom je richtlijnen voor je dashboards nodig hebt
Data dictionary
Power BI vertaalt dit naar een zogeheten dictionary, waarin elke unieke waarde uit de kolom zo gecomprimeerd mogelijk wordt opgeslagen. Hoe meer unieke waarden, hoe groter de dictionary is (hoe meer woorden je taal bevat, hoe groter je woordenboek zal zijn).
Om deze reden is het soms juist wél goed extra kolommen op te nemen, om zo je ‘woordenboek’ te verkleinen. Denk bijvoorbeeld aan het opdelen van tijdstempels in een los datumveld en een tijdveld.
Voorbeeld van het opsplitsen van kolommen
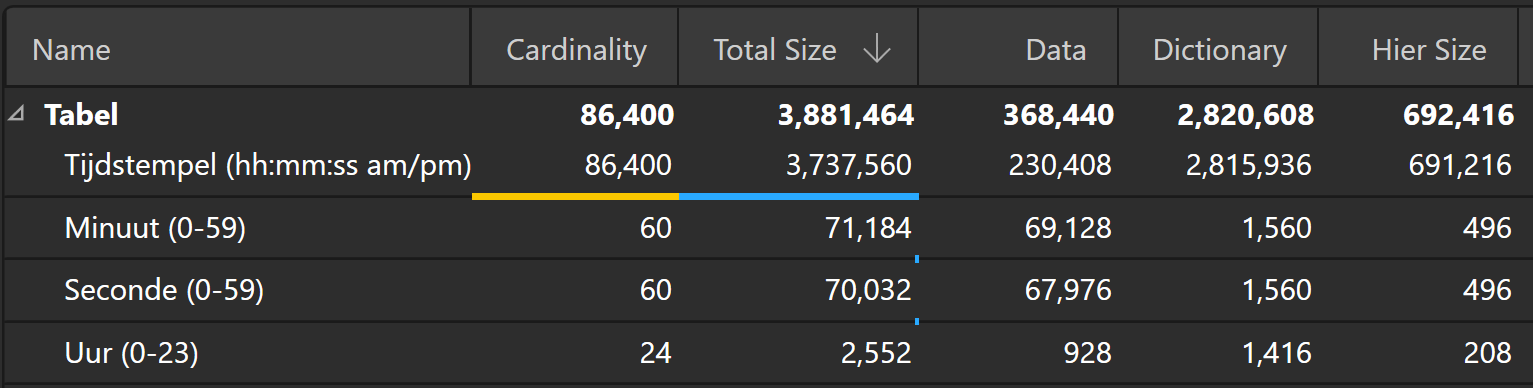
Het beste voorbeeld hiervan is het opdelen van tijdstempels (bijvoorbeeld 22-04-2022 14h:30m:24s) in een los datumveld en een tijdveld. Voor het hele jaar 2022 heeft het datumveld een cardinaliteit van 365 (het aantal dagen per jaar). Het tijdveld heeft een cardinaliteit van 24u60m60s= 86.400.
Zou je deze twee combineren tot één kolom, dan zal die kolom maar liefst 86.400*365 = 31.536.000 mogelijke combinaties van datums en tijd hebben. Ongeacht of elke combinatie daadwerkelijk voorkomt: je woordenboek zal veel groter zijn dan twee woordenboeken van de datumveld en tijdvelden samen. Namelijk 31.536.000 versus 365 en 86.400.
Voorbeeld van kardinaliteit in Power BI
We helpen je graag verder met het verbeteren van performance
Beperk de grootte van de waarden
De waarden in een cel van een tabel kunnen op verschillende manieren worden opgeslagen. Wat kan je doen om de opslaggrootte van de waarden in de tabellen te minimaliseren?
Modelleer de data met het stermodel
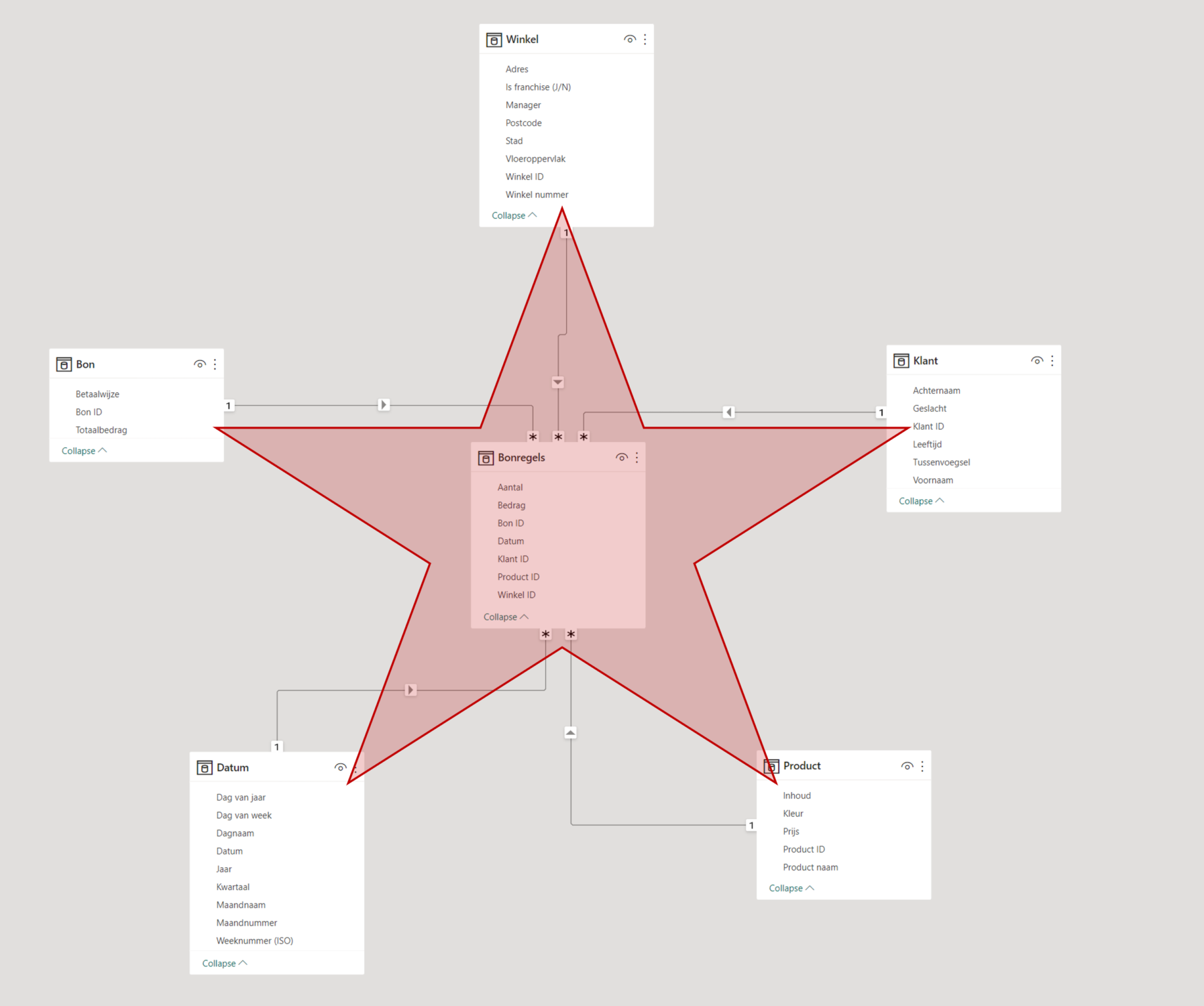
In dit voorbeeld hebben we beschikking over een dataplatform, waar de data volgens een ster gemodelleerd is. Dit betekent dat er zo min mogelijk informatie dubbel wordt opgeslagen. Zo wordt bij elke bonregel vastgelegd bij welk winkelnummer de aankoop is gedaan. In een aparte tabel worden alle kenmerken van de winkel beschreven (zoals de locatie, de grootte, openingstijden, etc.). Door de data als ster te modelleren hoeft deze informatie maar één keer te worden opgeslagen en niet voor elke bonregel herhaald te worden.
Voorbeeld van een stermodel
Data types en aantal decimalen
Hoe je de data in een kolom opslaat is ook van belang voor de grootte van het model. Hierboven is al beschreven wat er gebeurt met de omvang van de dictionary bij een grotere kardinaliteit. Het is daarom niet handig om bijvoorbeeld getallen met 10 decimalen achter de komma op te slaan. Meestal beperken we ons tot vier decimalen, zodat er geen verschillen in de afronding op centen ontstaat.
Bovenstaande voorbeelden laten zien waarom het belangrijk is vooraf na te denken over het reduceren van de grootte van de Power BI dataset. Zo werken de dashboards naar behoren en verloopt de adoptie binnen je organisatie vlekkeloos. Zo weet je zeker dat je collega’s het door jou gemaakte dashboard ook daadwerkelijk gebruiken. In veel gevallen is het af te raden om de BI-tool direct te koppelen aan de databronnen. Het gebruik van een datawarehouse als tussenlaag leidt dan tot een aanzienlijk betere performance.
Meer weten?
Wil je meer informatie over het optimaliseren van je datasets of het maken van interactieve dashboards? Neem dan vrijblijvend contact met ons op. Eén van onze specialisten neemt binnen één werkdag contact met je op. Of plan direct zelf een gratis adviesgesprek in op een dag en tijd die jou het best uitkomt.


