
Sinds versie 10 van MSTR is “visual insight” flink uitgebreid en ondersteunt de standaard bekende grafieken out of the box. Deze zijn inmiddels ook goed in te stellen naar wens qua kleuren, grootte, labels etc. Maar daar blijft het niet bij. Er is nog veel meer! Inmiddels is er ook verbeterde ondersteuning voor D3 visualisaties in VI dashboards. D3 is een open source javascript visualisatie bibliotheek geoptimaliseerd voor het weergeven van data in grote multidisciplinaire datasets. En daarin heb je dus de mogelijkheid om je eigen visualisatie te ontwikkelen. Je kan ook visualisaties van anderen gebruiken uit de D3community.
Microstrategy zet hierbij zijn beste beentje voor en heeft inmiddels een visualisatie gallery ontwikkeld, die je kan gebruiken met leuke voorbeelden van gave ‘minder standaard’ grafieken. Zoals bijv. een Sankey diagram, waterfall chart, timeline of een organizational chart. In de Visual Insight omgeving heb je de “Import Visualization” knop om een custom visualisatie te importeren.
Vervolgens kun je de data koppelen en properties instellen, zoals je dat voor ieder standaard grafiekje kan doen. Gaaf spul als je t mij vraagt!! Ik ga er vaak mee werken.
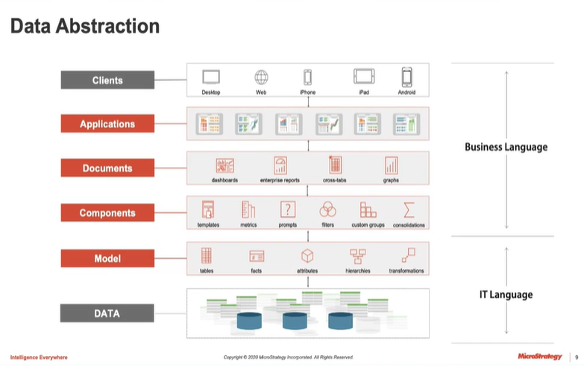
Dit alles heeft veel voordelen*, zoals:
- Objecten eenmalig aanmaken (eenduidige definities);
- Bij aanpassingen per object releasen (alles is een apart object met een uniek id);
- Afhankelijke objecten in kaart brengen (Forward and backward lineage);
- Ontkoppeling van onderliggend databaseplatform (eenvoudig om te mappen naar ander platform);
- Row based / object based security;
- Data beschikbaar stellen aan andere BI-tooling of platformen, indien gewenst (inprikken op MicroStrategy via Power BI of Tableau, maar ook middels Python, R of web-API toegang).
* de mogelijkheden verschillen per tool, MicroStrategy is marktleider op dit vlak, daar is bovenstaand lijstje op gebaseerd.
Valkuilen met Self-service BI
Je vraagt je inmiddels vast af: als we deze technologie allemaal al hebben, wat gaat er dan eigenlijk mis? Waarom vergeet men dan soms de basisprincipes van datawarehousing? De laatste jaren is selfservice BI enorm in opkomst.
Selfservice BI – iedere moderne BI tool ondersteunt het inmiddels, denk aan Power BI, Tableau, Quicksight of MicroStrategy – is heel krachtig. Het stelt business gebruikers in staat om heel snel van ruwe data tot informatie en inzichten te komen. Daarbij hoeft men niet te wachten tot de semantische laag klaar is (maar dat kan uiteraard wel), als men maar toegang heeft tot de data. Het is daarbij heel verleidelijk om te starten met het bouwen van dashboards, omdat de resultaten snel beschikbaar en presentabel zijn.
Toch moeten we daarbij niet vergeten om aan de basisprincipes van een datawarehouse vast te houden. Een valkuil waar men vaak intrapt is de zogenaamde “data first” approach. Daarbij gaan verschillende enthousiaste gebruikers of afdelingen aan de slag en creëren allemaal datasilo’s. Met als gevolg meerdere omgevingen en daarmee vervallen veel voordelen van een centraal datawarehouse.
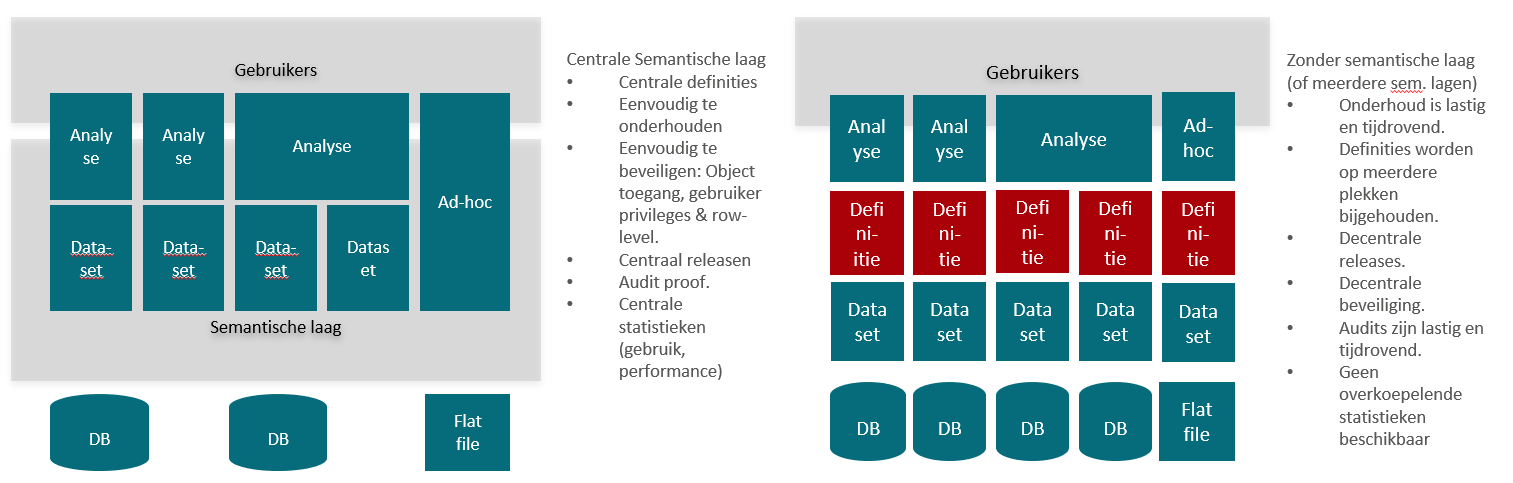
Op korte termijn is selfservice BI snel en eenvoudig, op langere termijn komen de – in eerste instantie – verborgen werkzaamheden naar boven. Het werken met een centrale semantische laag heeft uiteraard ook nadelen, want er moet wel eerst een basis semantische laag geïmplementeerd (en een onderliggend datamodel inclusief ETL- processen) zijn voordat de business aan de gang kan gaan met rapporten en dashboards. Dit hoeft echter niet vanaf de start altijd mega-complex te zijn. Een groot gedeelte van de semantische laag kan zelfs automatisch worden gegenereerd in MicroStrategy. Maar, als men haast heeft of bijvoorbeeld eerst wil bepalen of het de investering waard is, kan het dan niet allebei? Jazeker, dat noemen ze bij MicroStrategy: “BI-model BI”.
Lees meer: de vier grootste risico’s van Self Service BI.
BI-model BI
Simpel weg is “BI-model BI” eindgebruikers in staat stellen om zelf onderzoek naar data te doen en al een start te maken met het bouwen van dashboards, voordat de data in de centrale semantische laag beschikbaar is. Dat kan men doen door zelf data te importeren & koppelen in MicroStrategy en daarop een eigen eenvoudige semantische laag op te zetten binnen het centrale systeem.
Daarbij is men in staat om snel en onafhankelijk van IT-afdelingen inzichten te vergaren met alle mogelijkheden die het centrale platform biedt. Denk daarbij onder andere aan het koppelen met data welke reeds beschikbaar is op het platform of het centraal beschikbaar stellen van rapportages aan gebruikers. Als blijkt dat de nieuwe data toegevoegde waarde biedt, kan men vervolgens uiteraard de bron officieel laten ontsluiten en de al gebouwde rapportages & dashboards eenvoudig omhangen naar de centrale semantische laag (zonder opnieuw te ontwikkelen).
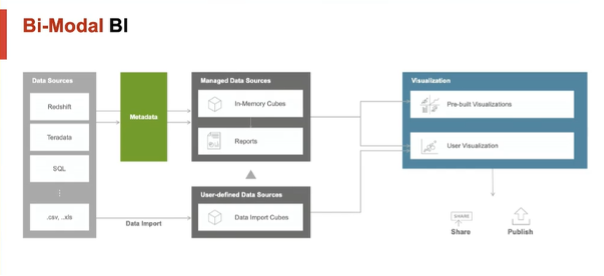
In MicroStrategy is BI-Model BI eenvoudig mogelijk via de “import data”& “vervang dataset” functionaliteit, iets waar klanten gretig gebruik van maken. Een mooie functionaliteit om de selfservice BI mogelijkheden van het platform te combineren met de kracht van de centrale semantische laag. Kortom: het beste van beide werelden op één centraal platform!


